Big Data - Lambda Architecture
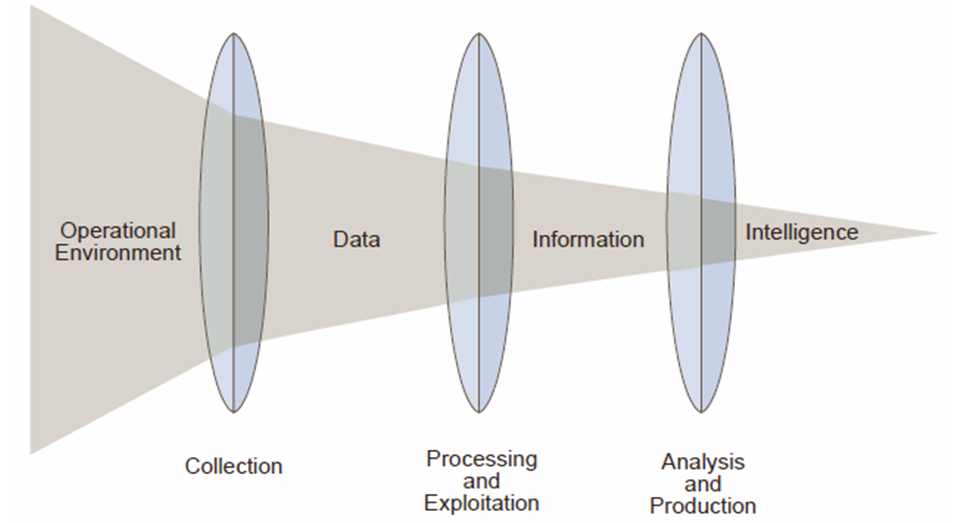
Date has a huge strategic business value. In fact this is the only resource on which a number of exceedingly successful businesses rely on e.g. Facebook, Twitter, Linkedin, Uber, Quora etc. These businesses are successful because of effective storage, processing and analysis of user provided data. To put it another way, today we have abundant, diverse and speed data (3 V's of big data) which require new data storage and processing framework.
Lambda architecture is a big data processing architecture. It involves batch and real-time stream processing to bring data in HDFS file system and serve (data) views to dependent applications. Batch processing takes care of views of batch or historical business data whereas stream processing details with real-time view of online data. Lambda architecture notably designed to deal with 3 V's (volume, velocity and veracity) of big data.
Lambda architecture consists of three layers:
-
Batch Layer
HDFS file system is the backbone of batch layer. To that end, batch layers stores (immutable, append-only) raw data. All subsequent updates are recorded as new events of a time series. There is an option to have pre-compute higher level logical views of raw data, which later be served to requesting applications. Raw data can be processed either in MapReduce or Spark framework. -
Serving Layer
This layer serves raw data or pre-computed views to requesting applications. One can think of scenarios like a custom application running on HBase or an SQL/analytics application on top of HDFS file system. - Speed Layer
This layer ingests data either through stream or batch processing framework. For instance, we can use Spark or Storm for online data or micro-batches process batch data and feed it to NoSQL data store like HBase or HDFS file system.
Broadly speaking, we can think of three possible solutions under Lambda architecture,;
-
ingest raw data in HDFS directly and host SQL-like application on top of it e.g. Impala
-
bring data into HDFS through HBase which sits in speed layer. Usually we preprocess raw data and then feed to HBase. This helps to increase performance.
- hybrid approach ingesting both processed and raw data. This kind of solutions are usually applied to implement complex data applications.
Significantly, Lambda architecture relies on open source software. The key strengths of this architecture are scalability of batch layer and real-time processing by speed layer. In Lambda architecture, the master (raw) data is alway denormalized for known performance reasons. On downside, open source software components along with denormalization poses a serious maintenance and reproduction challenge.